About FDABench
FDABench is a benchmark for evaluating data agents' reasoning ability over heterogeneous data in analytical scenarios.
It contains 2,007 tasks across different data sources, domains, difficulty levels, and task types.
We provide ready-to-use data agent implementations, a DAG-based evaluation system, and PUDDING, an agentic dataset construction framework that combines LLM generation with iterative expert validation.
Main performance metrics of different data agent systems are shown below; please check our Result for more details.
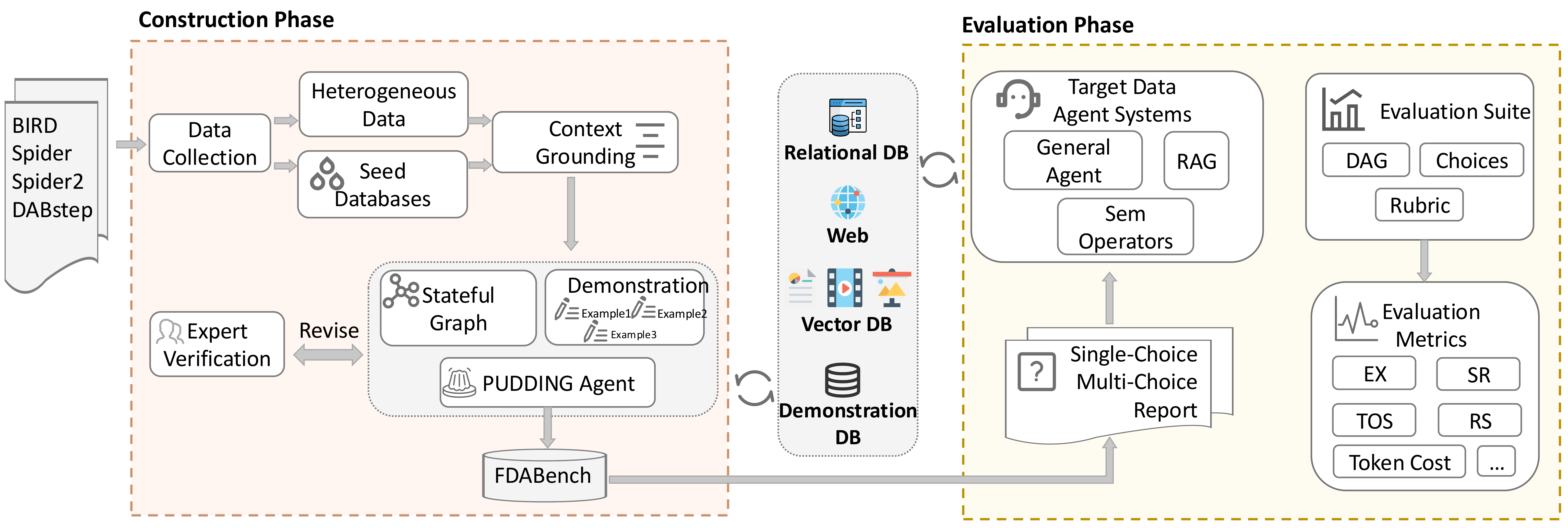
Illustrative Overview
FDABench comprises 2,007 analytical tasks across 50+ domains, covering structured databases, unstructured documents, web content, images, videos, and audio.
It supports three task types (single-choice, multiple-choice, and report generation) and four data agent workflow patterns (planning, tool-use, reflection, and multi-agent).
The evaluation suite includes choice correctness, rubric-based report scoring, and DAG-based reasoning trace metrics.
For more details, please check our paper.
Data
Our benchmark data can be directly downloaded on Hugging Face Datasets
. For code and implementation details, please visit our GitHub
repository for the complete FDABench implementation, including the 2,007 tasks across 50+ domains.
Acknowledgement
We thank Chuanjie Gong, Haoxuan Jia, Chuangxin Chu and Ruoxin Huang for their helpful feedback on this work. We also thank Huawei for their support in hosting the FDABench Challenge.
Submission
Submission Guideline
If you need to submit results, please submit them in JSONL format (JSON Lines - one JSON object per line) to
FDAbench2026@gmail.com.
Format Requirements: Each line should contain a complete JSON object with the following key fields:
- Basic fields:
task_id, instance_id, db, level, database_type, question_type
- For report tasks:
"generated_report": "your report content"
- For single choice:
"selected_answer": ["A"]
- For multiple choice:
"selected_answer": ["A", "C", "F"]
- Performance metrics:
latency, total_tokens, total_cost, etc.
Example format (one JSON object per line):
{"task_id": "FDA0014", "question_type": "report", "generated_report": "## Executive Summary\n\nBased on the analysis of ...", "confidence": 0.92, "execution_time": 8.5, "total_tokens": 3200}
{"task_id": "FDA0803", "question_type": "single_choice", "selected_answer": ["D"], "latency": "", "total_tokens": ""}
{"task_id": "FDA1415", "question_type": "multiple_choice", "selected_answer": ["A", "B", "D", "G"], "confidence": 0.88, "execution_time": 5.7, "total_tokens": 2300}
Citation
@article{wang2025fdabench,
title={FDABench: A Benchmark for Data Agents on Analytical Queries over Heterogeneous Data},
author={Wang, Ziting and Zhang, Shize and Yuan, Haitao and Zhu, Jinwei and Li, Shifu and Dong, Wei and Cong, Gao},
journal={arXiv preprint arXiv:2509.02473},
year={2025}
}